Что такое data science и как это работает?
Содержание:
- Хорошие конференции и митапы
- Образование в области Data Science: ничего невозможного нет
- Какие языки стоит изучить
- Что мне нравится в моей работе
- Кто он, Data Scientist?
- Как лучше хранить данные, если вы дата-сайентист
- Этап 6
- Подборка хороших курсов
- В каких случаях становятся специалистом по Data Science?
- Требования к специалисту
- Пример: профилактика диабета
- Какие задачи решает?
- Кто такой Data Scientist и чем занимается?
- С чего начать обучение Data Science самостоятельно
- Где учиться на Data Scientist — специалиста по большим данным
- «Самая сексуальная профессия»
Хорошие конференции и митапы
International Conference on Big Data and its Applications (ICBDA)
- Самая серьезная конференция по Big Data на русском языке/li>
- Участвуют представители бизнеса, научные сотрудники, ученые и создатели новых технологий
- Включает соревнования, научный семинар, выставку
- Крупнейшая международная конференция, которая сегодня проводится в крупнейших технологических центрах, таких как Сан-Хосе,Нью-Йорк, Лондон и другие
- Все звезды и все новинки — здесь
- Кроме конференции проводятся воркшопы и обучение, возможно также онлайн-участие
- Ежегодный фестиваль и IT-форум, посвященный анализу данных, проходящий в Москве
- Для профессионалов в области Big Data и новичков в этой сфере
- Большие данные, искусственный интеллект, глубинное обучение, множество бизнес-кейсов
- Ежегодная конференция по Data Science, проходящая раз в год в Москве
- Для разработчиков, инженеров, исследователей
- Кейсы, на примере которых наглядно показывается, почему не стоит забивать гвозди микроскопом
- Одно из самых крупных и живых сообществ по анализу данных в рунете
- В основе — групповой чат Slack
- Здесь можно проконсультироваться, узнать о новых технологиях, найти работу и найти data scientist’а
- Группа, посвященная митапам по Data Science в Москве
- Анонсы встреч, лекций, мастер-классов, выступлений, обсуждений — все на тему Data Science
- Для людей, занимающихся и интересующихся анализом, визуализацией данных и майнингом
Образование в области Data Science: ничего невозможного нет
Сегодня для тех, кто хочет развиваться в сфере анализа больших данных, существует очень много возможностей: различные образовательные курсы, специализации и программы по data science на любой вкус и кошелек, найти подходящий для себя вариант не составит труда. С моими рекомендациями по курсам можно ознакомиться здесь.
Потому как Data Scientist — это человек, который знает математику. Анализ данных, технологии машинного обучения и Big Data – все эти технологии и области знаний используют базовую математику как свою основу.
Читайте по теме: 100 лучших онлайн-курсов от университетов Лиги плюща Многие считают, что математические дисциплины не особо нужны на практике. Но на самом деле это не так.
Приведу пример из нашего опыта. Мы в E-Contenta занимаемся рекомендательными системами. Программист может знать, что для решения задачи рекомендаций видео можно применить матричные разложения, знать библиотеку для любимого языка программирования, где это матричное разложение реализовано, но совершенно не понимать, как это работает и какие есть ограничения. Это приводит к тому, что метод применяется не оптимальным образом или вообще в тех местах, где он не должен применяться, снижая общее качество работы системы.
Хорошее понимание математических основ этих методов и знание их связи с реальными конкретными алгоритмами позволило бы избежать таких проблем.
Кстати, для обучения на различных профессиональных курсах и программах по Big Data зачастую требуется хорошая математическая подготовка.
«А если я не изучал математику или изучал ее так давно, что уже ничего и не помню»? — спросите вы. «Это вовсе не повод ставить на карьере Data Scientist крест и опускать руки», — отвечу я.

Есть немало вводных курсов и инструментов для новичков, позволяющих освежить или подтянуть знания по одной из вышеперечисленных дисциплин. Например, специально для тех, кто хотел бы приобрести знания математики и алгоритмов или освежить их, мы с коллегами разработали специальный курс GoTo Course. Программа включает в себя базовый курс высшей математики, теории вероятностей, алгоритмов и структур данных — это лекции и семинары от опытных практиков
Особое внимание отведено разборам применения теории в практических задачах из реальной жизни. Курс поможет подготовиться к изучению анализа данных и машинного обучения на продвинутом уровне и решению задач на собеседованиях
|
15 сентября в Москве состоится конференция по большим данным Big Data Conference. В программе — бизнес-кейсы, технические решения и научные достижения лучших специалистов в этой области. Приглашаем всех, кто заинтересован в работе с большими данными и хочет их применять в реальном бизнесе. |
Ну а если вы еще не определились, хотите ли заниматься анализом данных и хотели бы для начала оценить свои перспективы в этой профессии, попробуйте почитать специальную литературу, блоги о науке данных или посмотреть лекции. Например, рекомендую почитать хабы по темам Data Mining и Big Data на Habrahabr. Для тех, кто уже хоть немного в теме, со своей стороны порекомендую книгу «Машинное обучение. Наука и искусство построения алгоритмов, которые извлекают знания из данных» Петера Флаха — это одна из немногих книг по машинному обучению на русском языке.
Заниматься Data Science так же трудно, как заниматься наукой в целом. В этой профессии нужно уметь строить гипотезы, ставить вопросы и находить ответы на них. Само слово scientist подталкивает к выводу, что такой специалист должен, прежде всего, быть исследователем, человеком с аналитическим складом ума, способный делать обоснованные выводы из огромных массивов информации в достаточно сжатые строки. Скрупулезный, внимательный, точный — чаще всего он одновременно и программист, и математик.
Какие языки стоит изучить
Для работы в сфере научной обработки данных следует изучать языки программирования. Распространены среди новичков Python и R. Также аналитики используют языки Java, SQL, Scala.
Python
Язык создан в 1991 году, в русском языке распространено название питон. Имеет бесплатную лицензию.
Преимущества:
- простота изучения;
- надежность;
- широкое распространение гарантирует поддержку разработчиков.
Среди недостатков пользователи отмечают появление сообщений об ошибках из-за динамичной типизации языка. Для узких целей статистического анализа уступает языку R.
R
Язык программирования R появился в 1995 году. Лицензия бесплатна.
Плюсы:
- многообразие специализированных пакетов с открытым исходным кодом;
- доступность большого числа статистических функций;
- яркая визуализация данных.
Ему присуща медлительность обработки информации.
Что мне нравится в моей работе
Я работаю в «Тинькофф» уже три с половиной года. В нашей компании много задач для сайентистов и почти нет ограничений по развитию. Наука о данных — достаточно универсальная область
По сути тебе не важно какими данными ты занимаешься: о торговле продуктами или о поведении пользователей в интернете. Для всех задач есть одинаковая база: математика и программирование
Зная базовые вещи уже можно углубляться в конкретные области, например, компьютерное зрение или обработку естественного языка.
Большинство задач в индустрии довольно стандартные, они ориентированы прежде всего на бизнес-результат. Поэтому в какой-то момент каждому специалисту хочется начать делать что-то свое параллельно основной работе. Я, например, хотел бы привнести что-то новое в open-source (программы и технологии для разработчиков), но пока своих значимых кейсов нет.
Мне нравится создавать технологии, которые автоматизируют ручную работу. Например, известная в машинном обучении библиотека scikit-learn поделила профессию на «до» и «после»: у разработчиков появились инструменты для быстрой работы с алгоритмами ML.
Еще мне хотелось бы углубиться в другие области машинного обучения. Я занимаюсь временными рядами, обычно в этой специализации лучше работают классические модели. И хочу поглубже копнуть в Deep Learning — глубинное обучение, где нейросети способны решать очень сложные задачи. Именно в этой области сейчас происходят наиболее интересные в машинном обучении вещи.
Курс
Полный курс по Data Science
Освойте востребованную профессию с нуля за 12 месяцев и станьте уверенным junior-специалистом.
- Индивидуальная поддержка менторов
- 10 проектов в портфолио
- Помощь в трудоустройстве
Получить скидку Промокод “BLOG10” +5% скидки
Кто он, Data Scientist?
Вообще-то Data Scientist — профессия, окруженная разными мифами. В глазах одних Data Scientists — это подобие шаманов, способных из «больших данных добывать нефть», причем знаний в области бизнеса от них не требуется. Другие причисляют к этой профессии вообще почти любого программиста: умеешь программировать — умеешь работать с данными.
Мне ближе определение, которое дает специалист по биологической статистике Джеффри Лик из Университета Джонса Хопкинса. Data Scientist — это специалист, владеющий тремя группами навыков:
- IT-грамотность — программирование, придумывание и решение алгоритмических задач, владение софтом;
- Математические и статистические знания;
- Содержательный опыт в какой-то области — понимание бизнес-запросов своей организации или задач своей отрасли науки.
Причем вакансии, подразумевающие эту специализацию, могут называться по-разному. Среди самых популярных названий — аналитик Big Data, математик или математик-программист, менеджер по анализу систем, архитектор Big Data, бизнес-аналитик, BI-аналитик, информационный аналитик, специалист Data Mining, инженер по машинному обучению и многие другие.
Как лучше хранить данные, если вы дата-сайентист
Обычно Аркадий работает с небольшими датасетами и хранит их в файлах от 50 до 100 Мб. Но с новым проектом к нему пришел большой набор данных, и Аркадий решил как обычно сложить его в csv-файл, который получился объемом 13 Гб. И здесь начинаются проблемы.
Такой файл сложно передать кому-то из коллег: вы будете очень долго ждать, пока он загрузится в Slack или Google Drive. А еще он может вообще не открыться на компьютере. Или формат такого файла плохо доходит до прода: объем данных растет с каждым днем и файл разрастается.
Что же можно с этим сделать? Посмотрим, как хранят файлы разработчики.
-
Они используют базы данных, оптимизированные под свои задачи и под тот объем данных, который у них есть.
-
Валидируют форматы данных при загрузке.
-
Поддерживают отказоустойчивость сервисов и баз данных, которые к ним подключены.
-
Заранее думают о возможностях масштабирования. То есть сразу прогнозируют, насколько объем данных вырастет через год, и нужно ли будет переделывать архитектуру с нуля, или у них будет возможность масштабироваться до нужного объема.
Конечно, дата-сайентистам не всегда нужно делать отказоустойчивые сервисы, но тем не менее, они могут подсмотреть некоторые штуки, которые облегчат работу.
Мы уже поняли, что сохранять все в csv-формате — не вариант. Такой файл не влезет в RAM среднестатистического компьютера, а скорость чтения явно превысит 2 минуты. В этом случае нет никакой оптимизации, валидации форматов, отказоустойчивости и масштабируемости.

Попробуем разделить этот файл по отдельным партициям. Например, найти колонку с маленькой вариативностью данных, по которой можно разделить их и сложить в отдельные файлы. После этого мы сможем обрабатывать отдельные файлы под необходимые задачи. Так мы решаем проблему масштабируемости, но размер файлов все равно остается большим.
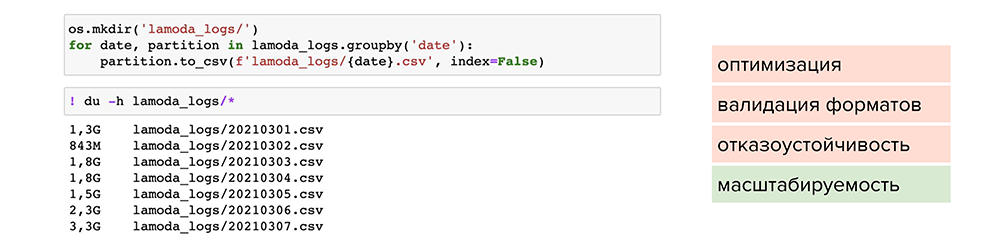
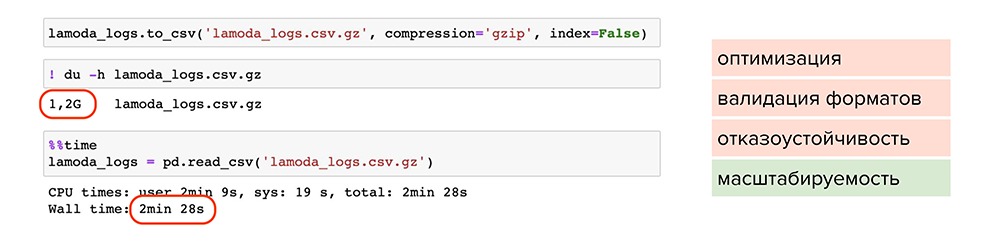
Теперь попробуем сжать файлы. Например, можно воспользоваться обычной утилитой сжатия для одного файла gzip. Она доступна в pandas, нужно лишь при сохранении указать ее в параметре , и файл станет весить 1,2 Гб вместо 13 Гб. Но читается он также 2 минуты. Делаем вывод, что такой способ мало подходит для оптимизации, хотя масштабируемость присутствует — файлы стали занимать меньше места на диске.
Попробуем улучшить результат. Например, можно использовать parquet — это специальный формат сжатия или, более умными словами, партиционированная бинарная колоночная сериализация для табличных данных. Он позволит работать с каждым типом данных в каждой колонке отдельно: например, сжимать числовые данные одним способом, текстовые или строковые данные — другим способом, и таким образом оптимизировать как хранение информации, так и чтение.
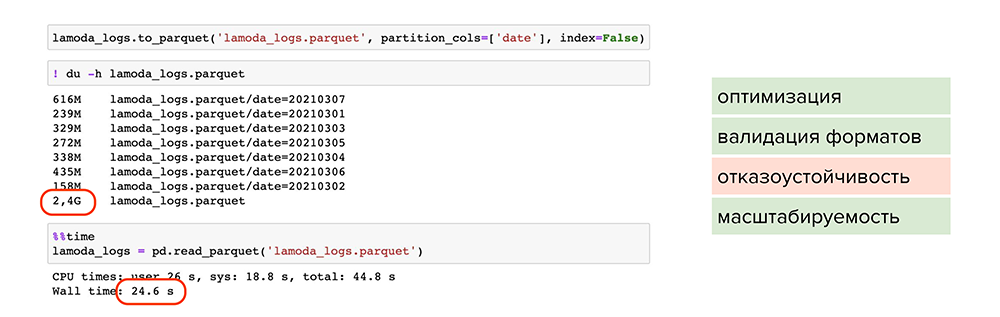
С применением parquet:
-
Большой объем данных стал весить 2,4 Гб и читаться за 24 секунды. Файлы оптимально сжаты, поделены на партиции и у каждого есть метаданные.
-
Происходит валидация форматов, поскольку parquet работает с каждым форматом колонки отдельно и проверяет их при записи. Вероятность записать ошибочные данные снижается.
-
Присутствует масштабируемость, поскольку мы пишем данные в разные партиции и сжимаем их.
Однако мы не победили один пункт — отказоустойчивость.
Чтобы покрыть все пункты, можно обратиться к специальным фреймворкам и базам данных. Например, подойдут ClickHouse или Hadoop, особенно, если это продакшн-решения или повторяющиеся истории.
Этап 6
Углубление и развитие технических навыков
Если предыдущие этапы давали вам навыки, без которых работать ну вообще нельзя, то навыки этого этапа призваны повысить вашу продуктивность или повысить качество решаемых задач, повысить самостоятельность при запуске разработанных моделей машинного обучения в продакшн.
-
Python на хорошем уровне: декораторы, уверенное знание классов и наследования, изучение базовых классов, dunderscore __методы__ .
-
Уверенное пользование bash, понимание основ linux
-
Полезно изучить основы docker
Все эти вещи можно было бы учить и раньше. Но, как правило, раньше их знать просто не нужно. Т.к. вы больше будете страдать от нехватки других навыков, приведенных в предыдущих этапах.
Другие области машинного обучения
В какой-то момент вам может потребоваться выйти из сферы подготовки прогнозных моделей или изучения и объяснения данных (кластеризация, EDA и визуализация). Это может быть связано как с вашими интересами, так и с проектами на работе. Например, это могут быть рекомендательные системы. Наверное, базовые рекомендательные алгоритмы можно изучать и одновременно с основами машинного обучения, т.к. знание одного не является обязательным для знания другого. Но логичнее переходить к ним, когда вы уже разобрались с основными алгоритмами обучения прогнозирования и кластеризации: скорее всего, этого от вас будут ожидать любые коллеги до тех пор, как вы включитесь в работу над рекомендательными системами.
Нейронные сети
Начиная с этого этапа имеет смысл изучать нейронные сети как следует с тем, чтобы применять их на пратике. Неэффективно изучать их раньше, т.к. многие задачи эффективно можно решить другими методами. И пока ваши данные и прогнозы изначально числовые, обычно «классическими» методами их решать эффективнее.
Подробнее в этапы изучениях нейронных сетей вдаваться не стану: эта тема требует отдельной статьи. И потратить на них можно от 50, чтобы решать самые простейшие задачи, до сотен часов, чтобы решать задачи связанные с обработкой неструктурированных данных или с обучением сложных моделей.
Подборка хороших курсов
- Практический курс по машинному обучению с менторской поддержкой
- Курс содержит полный обзор современных методов машинного обучения от простых моделей до работы с нейросетями и Big Data от опытного практика области
- Специализация Яндекса и МФТИ на Coursera на русском языке
- Полное введение в data science и машинное обучение на базе Python
- Теорию можно смотреть бесплатно, задания и сертификат — платные
- Интерактивное пошаговое изучение Data Science с фокусом на Python
- Обучение через практику: с самого начала работа с реальными данными и кодом
- 3 направления на выбор: Data Scientist, Data Analyst или Data Engineer
- Интерактивный онлайн-курс по Data Science с фокусом на R
- 66 курсов по машинному обучению, анализу данных и статистике
- Курс построен на решении практических задач
«Специализация Аналитик Данных»
- Специализация включает сквозной курс и тренажёры по инструментам для анализа данных.
- Срок обучения: 6 месяцев
- Онлайн-программа профессиональной переподготовки от Института биоинформатики и Санкт-Петербургского Академического университета РАН, не требующая специальной подготовки
- Срок обучения: 1 год. С лета 2017 — ускоренная программа (полгода)
- Стоимость: 1999 рублей в месяц
Курс по математике для Data Science
Курс содержит много практики, которая не ограничивается решением классических уравнений и абстрактных заданий.
Основы статистики
Бесплатное и ясное введение в математическую статистику для всех
- Легендарный курс основателя Coursera и одного из лучших специалистов по искусственному интеллекту Эндрю Ын (Andrew Ng)
- Этот курс можно считать индустриальным стандартом по введению в машинное обучение
- Добрый человек “перевел” задания на Python (в оригинале нужно все делать на Octave)
- Курс от NVIDIA и SkillFactrory
- Комплексный курс по глубокому обучению на Python для начинающих
- Видеозаписи занятий легендарной Школы анализа данных Яндекса
- Курсы: машинное обучение, алгоритмы и структуры данных, параллельные вычисления, дискретный анализ и теория вероятности и др.
“10 онлайн-курсов по машинному обучению”
Подборка удаленных образовательных программ, составленная проектом “Теплица социальных технологий”
- Любопытное введение в статистику на примере … котиков
- Вы получите знания об основах описательной статистики, дисперсионном и корреляционном анализе
- Фишка курса — наглядность (опять же картинки с котиками)
- Учит извлекать данные из разных файлов, баз данных и API
- Преобразовывать данные для удобного анализа
- Интерпретировать и визуализировать результаты анализа
Курс по Python для анализа данных
Практический курс по Python для аналитиков с менторской поддержкой.
- Курс от Высшей школы экономики
- Онлайн-курс по самому популярному языку программирования для data scientist’ов
В каких случаях становятся специалистом по Data Science?
- Когда нравится анализ и систематизация данных и есть интерес к передовым технологиям — дата-сайентисты работают с искусственным интеллектом, нейросетями и большими данными.
- Когда хочется заниматься исследованиями и наукой на качественно новом уровне.
- Когда есть опыт в обычной разработке и есть желание освоить больший набор инструментов и заниматься масштабными проектами.
- Когда на текущей работе мало перспектив, хочется освоить перспективное направление и больше зарабатывать.

Глеб Синяков
аналитик-разработчик в «Тинькофф»
Всех, кто приходит в Data Science, можно разделить на четыре потока. Есть те, кто становятся дата-сайентистами после профессионального образования, но в университетах таких курсов пока немного. Также есть люди технических и научных профессий, которые хотят найти более перспективную работу с большой зарплатой. Третий поток — разработчики, которые устают от скучного программирования и ищут интересные задачи. Есть специалисты, которые начинали с нуля: если у новичков есть самодисциплина и интерес к большим данным, то они становятся хорошими дата-сайентистами. Наконец, есть те, к кому Data Science приходит сам, например к биоинформатикам.
Подробнее о том, чем занимается Глеб Синяков, читайте в рассказе о его профессии.
Требования к специалисту
Специалист по данным неразрывно связан с Data Science – наукой о данных. Она находится на пересечении нескольких направлений: математики, статистики, информатики и экономики. Следовательно, специалисты должны понимать и интересоваться каждой из этих наук.
Кроме этого, Data Scientist должен знать:
- Языки программирования для того, чтобы писать на них код. Самые распространенные – это SAS, R, Java, C++ и Python.
- Базы данных MySQL и PostgreSQL.
- Технологии и инструменты для представления отчетов в графическом формате.
- Алгоритмы машинного и глубокого обучения, которые созданы для автоматизации повторяющихся процессов с помощью искусственного интеллекта.
- Как подготовить данные и сделать их перевод в удобный формат.
- Инструменты для работы с Big Data: Hadoop, MapReduce, Apache Hive, Apache Kafka, Apache Spark.
- Как установить закономерности и видеть логические связи в системе полученных сведений.
- Как разработать действенные бизнес-решения.
- Как извлекать нужную информацию из разных источников.
- Английский язык для чтения профессиональной литературы и общения с зарубежными клиентами.
- Как успешно внедрить программу.
- Область деятельности организации, на которую работает.
Помимо того, что специалист по данным должен обладать аналитическим и математическим складом ума, он также должен быть:
- трудолюбивым,
- настойчивым,
- скрупулезным,
- внимательным,
- усидчивым,
- целеустремленным,
- коммуникабельным.
Хочу отметить, что гуманитариям достичь высот в этой профессии будет крайне тяжело. Только при большом желании можно пробовать осваивать данную стезю.
Пример: профилактика диабета
Что, если мы сможем предсказать возникновение диабета и предпринять соответствующие меры заранее, чтобы предотвратить его?
В этом случае мы прогнозируем появление диабета, используя весь жизненный цикл, о котором мы говорили ранее. Давайте рассмотрим различные шаги.
Шаг 1:
Во-первых, мы собираем данные на основе истории болезни пациента, как описано в Фазе 1. Вы можете обратиться к приведенным ниже примерам.
Данные
Как вы можете видеть, у нас есть различные атрибуты, как указано ниже.Атрибуты:
npreg — Количество беременности
glucose — Концентрация глюкозы в плазме
bp — Кровяное давление
skin — Толщина кожи трицепса
bmi — Индекс массы тела
ped — Функция родословной диабета
age — Возраст
income — Доход
Шаг 2:
Теперь, как только у нас появились данные, нам необходимо очистить и подготовить их для анализа.
Эти данные имеют множество несоответствий, таких как отсутствующие значения, пустые столбцы, неожиданные значения и неправильный формат данных, которые необходимо очистить.
Здесь мы организовали данные в одну таблицу под разными атрибутами, что делает ее более структурированной.
Давайте посмотрим на примеры ниже.
Очистка данных
Эти данные имеют много несоответствий.
В столбце npreg слово «one» написано словами, тогда как оно должно быть в числовой форме.
В столбце bp одно из значений — 6600, что невозможно (по крайней мере для людей), поскольку bp не может доходить до такого огромного значения.
Как вы можете видеть, столбец «income» пуст, в этом случае не имеет смысла прогнозировать диабет. Поэтому иметь его здесь избыточно и это нужно удалить из таблицы.
Таким образом, мы очистим и обработаем данные, удалив выбросы, заполнив нулевые значения и нормализуя типы данных. Если вы помните, это наш второй этап, который представляет собой предварительную обработку данных.
Наконец, мы получаем чистые данные, как показано ниже, которые можно использовать для анализа.
Очищенные данные
Шаг 3:
Теперь давайте сделаем некоторый анализ, как обсуждалось ранее в Фазе 3.
Сначала мы загрузим данные в аналитическую песочницу и применим к ней различные статистические функции. Например, R имеет такие функции, как describe, которое дает нам количество отсутствующих значений и уникальных значений. Мы также можем использовать summary функцию, которая даст нам статистическую информацию, такую как средние, медианные, диапазонные, минимальные и максимальные значения.
Затем мы используем методы визуализации, такие как гистограммы, линейные графики, полевые диаграммы (histograms, line graphs, box plots), чтобы получить представление о распределении данных.
Data Science визуализация
Шаг 4:
Теперь, основываясь на представлениях, полученных на предыдущем шаге, наилучшим образом подходит для этой проблемы — дерево решений (decision tree).
Поскольку у нас уже есть основные атрибуты для анализа, такие как npreg, bmi и т. Д., Поэтому мы будем использовать метод обучения с учителем для создания модели.
Кроме того, мы использовали дерево решений, потому что оно учитывает все атрибуты за один раз, например, те, которые имеют линейную связь, а также те, которые имеют нелинейную взаимосвязь. В нашем случае мы имеем линейную зависимость между npreg и age, тогда как существует нелинейная связь между npreg и ped.
Модели дерева решений очень надежны, так как мы можем использовать различную комбинацию атрибутов для создания различных деревьев, а затем, наконец, реализовать ту, которая имеет максимальную эффективность.
Давайте посмотрим на наше дерево решений.
Дерево решений
Здесь самым важным параметром является уровень глюкозы, поэтому это наш корневой узел. Теперь текущий узел и его значение определяют следующий важный параметр. Это продолжается до тех пор, пока мы не получим результат в терминах pos или neg. Pos означает, что тенденция к диабету является положительной, а neg отрицательной.
Шаг 5:
На этом этапе мы проведем небольшой пилотный проект, чтобы проверить, соответствуют ли между собой наши результаты. Мы также будем искать ограничения производительности, если таковые имеются. Если результаты неточны, нам нужно перепланировать и перестроить модель.
Шаг 6:
Как только мы выполним проект успешно, мы будем делиться результатами для полного развертывания.
Data Scientist’у проще сказать, чем сделать. Итак, давайте посмотрим, что вам нужно, чтобы быть им. Data Science требует навыков в основном из трех основных областей, как показано ниже.
Data Science умения и навыки
Как вы можете видеть на приведенном выше графике, вам нужно приобрести различные умения и навыки. Вы должны хорошо разбираться в статистике и математике для анализа и визуализации данных.
Какие задачи решает?
Data scientists извлекают, анализируют и интерпретируют большие объемы данных из различных источников, используя алгоритмы, интеллектуальный анализ данных, искусственный интеллект, машинное обучение и инструменты статистического учета, чтобы создавать из них бизнес-модели. После интерпретации результаты должны быть изложены понятным и интересным языком.
Специалисты по обработке данных пользуются большим спросом в ряде секторов, поскольку предприятиям требуются люди с правильным сочетанием технических, аналитических и коммуникативных навыков. Data scientists могут работать в различных областях, в том числе:
- коммерции;
- образовании;
- науке;
- здравоохранении;
- розничной торговле;
- информационных технологиях;
- правительственных организациях;
- электронной коммерции (бизнесе онлайн).
Как специалист сайентист должен выполнять следующее:
- работать в тесном сотрудничестве с руководством компании, чтобы выявлять проблемы и использовать имеющиеся сведения, и предлагать варианты для эффективного принятия решений;
- создавать алгоритмы и разрабатывать эксперименты для объединения, управления, опроса и выделения данных для предоставления индивидуальных отчетов коллегам, клиентам или всей организации;
- использовать инструменты машинного обучения и статистические методы для решения проблем;
- тестировать модели интеллектуального анализа данных, чтобы выбрать наиболее подходящие для использования в конкретном проекте;
- поддерживать четкую и последовательную коммуникацию (как устную, так и письменную), чтобы понимать потребности в данных и сообщать о результатах;
- создавать отчеты, которые позволят четко понять, как клиенты или посетители взаимодействуют с компанией;
- оценить эффективность источников данных и методов их сбора данных и улучшать их;
- постоянно повышать квалификацию, чтобы оставаться в курсе последних технологий и методов;
- проводить исследования, на основе которых будут разрабатываться прототипы и доказательства концепций;
- искать возможности использовать соотношения идей, наборы данных, кодов и моделей в других структурах организации (например, в отделах кадров и маркетинга);
- сохранять заинтересованность по поводу использования алгоритмов для решения проблем и давать другим возможность видеть пользу от своей аботы.
Кто такой Data Scientist и чем занимается?
Данные — основной объект исследования в Big Data. Вопреки стереотипам, аналитики Data Scientist работают не только в крупных компаниях. В молодой индустрии Big Data инженеры, математики, программисты и трейдеры создают визуальные модели, формируют бизнес-сценарии и тестируют их. Прогнозы экспертов интересны широкому кругу лиц — компаниям, частным предпринимателям, государственным учреждениям. Анализ Big Data — это не только статистические обзоры, но и предвидение будущих событий, вероятность которых можно вывести с математической точностью. Курс Data Scientist от Skillbox отличается насыщенной программой. Слушателей знакомят с нейронными сетями, инфографикой, работой в библиотеках.
С чего начать обучение Data Science самостоятельно
Научиться основам Data Science с нуля можно примерно за год. Для этого нужно освоить несколько направлений.
Python. Из-за простого синтаксиса этот язык идеально подходит для новичков. Со знанием Python можно работать и в других IT-областях, например веб-разработке и даже гейм-дизайне. Для работы нужно также освоить инструменты Data Science, например Scikit-Learn, которые упрощают написание кода на Python.
Математика. Со знанием Python уже можно работать ML-инженером. Но для полного цикла Data Science нужно уметь работать с математическими моделями, чтобы анализировать данные. Для этого изучают линейную алгебру, матанализ, статистику и теорию вероятностей. Также математика нужна, чтобы понимать, как устроен алгоритм, и уметь подобрать правильные параметры для задачи.
Машинное обучение. Используйте знания Python и математики для создания и тренировки ML-моделей. Код для моделей и наборы данных для обучения (датасеты) можно найти, например, на сайте Kaggle. Подробнее о том, зачем дата-сайентисту Kaggle, читайте в статье.
Визуальный анализ данных (EDA) отвечает на вопросы о том, что происходит внутри данных, позволяет найти выбросы в них и получить инсайты про создание уникальных фичей для будущего алгоритма.
Вот несколько полезных ссылок для новичков:
Книги:
«Изучаем Python», Марк Лутц.
«Python и машинное обучение. Машинное и глубокое обучение с использованием Python, scikit-learn и TensorFlow», Себастьян Рашка, Вахид Мирджалили.
«Теория вероятностей и математическая статистика», Н. Ш. Кремер.
«Курс математического анализа» Л. Д. Кудрявцев.
«Линейная алгебра», В. А. Ильин, Э. Г. Позняк.
Курсы:
Питонтьютор — бесплатный практический курс Python в браузере.
Бесплатный курс по Python от Mail.ru и МФТИ на Coursera.
Модуль по визуализации данных из курса Mail.ru и МФТИ.
Фреймворки, модели и датасеты
Основные библиотеки: NumPy, Scipy, Pandas.
Библиотеки для машинного и глубокого обучения: Scikit-Learn, TensorFlow, Theano, Keras.
Инструменты визуализации: Matplotlib и Seaborn.
Статья на хабре со ссылками на модели из разных сфер бизнеса на GitHub.
Список нужных фреймворков, библиотек, книг и курсов по машинному обучению на GitHub.
Kaggle — база моделей и датасетов, открытые соревнования дата-сайентистов и курсы по машинному обучению.
Дата-сайентистом можно стать и без опыта в этой сфере. За 13 месяцев на курсе по Data Science вы изучите основы программирования и анализа данных на Python, научитесь выгружать нужные данные с помощью SQL и делать анализ данных с помощью библиотек Pandas и NumPy, разберетесь в основах машинного обучения. После обучения у вас будет 8 проектов для портфолио.
Курс
Data Science с нуля
Станьте востребованным специалистом на рынке IT! За 13 месяцев вы получите набор компетенций, необходимый для уровня Junior.
- структуры данных Python для проектирования алгоритмов;
- как получать данные из веб-источников или по API;
- методы матанализа, линейной алгебры, статистики и теории вероятности для обработки данных;
- и многое другое.
Узнать больше
Промокод “BLOG10” +5% скидки
Где учиться на Data Scientist — специалиста по большим данным
Изучение науки о данных с нуля лучше начинать сразу после окончания школы. Немногие ВУЗы обучают дата-сайентистов. Профессиональных аналитиков готовят по специальным программам ряд учебных заведений. Среди них:
- Высшая Школа Экономики (ВШЭ) – факультет компьютерных наук – магистерская программа на русском и английском языках;
- Московский физико-технический институт (МФТИ) – факультет инноваций и высоких технологий – магистратура;
- Московский государственный университет имени М.В.Ломоносова (МГУ) – факультет вычислительной математики и кибернетики – магистерская программа на 2 года;
- Санкт-Петербургский государственный университет (СПбГУ) – 2-годовая программа магистратуры на английском языке «Бизнес аналитика и большие данные».

Существуют некоммерческие курсы дополнительного образования для лиц любого возраста. Обучаться на них можно после сдачи вступительных экзаменов, преодолев необходимый порог по баллам. Срок обучения – 2 года.
Список курсов для подготовки специалистов в сфере Data science:
- Школа Анализа Данных Яндекса;
- Технопарк Mail.ru и МГТУ имени Баумана (упор на обучение системных инженеров);
- Центр компьютерных наук (Яндекс с Jet Brains);
- Петербургская школа данных (компания E-Contenta).
В интернете много коммерческих курсов по анализу данных. Их стоимость составляет 100-200 тысяч рублей. Срок обучения – от 2 до 8 месяцев. Перевод денег за учебу осуществляйте, убедившись, что выбранные курсы – не лохотрон, разводящий «чайников».
Удаленно обучиться анализу данных можно в институте интернет-профессий Нетология. В зависимости от раздела Data Science, стоимость курсов составляет от 25 до 200 тысяч рублей. Полная информация размещена на официальном сайте https://netology.ru/.
Компания Open Data Science обучает новичков и создает совместные аналитические проекты. Она организует бесплатные международные конференции по актуальным вопросам и направлениям развития, проводит конкурсы среди дата-сайентистов.
В сети доступны видео-уроки, книги, онлайн-лекции по этой тематике.
«Самая сексуальная профессия»
Как написал несколько лет назад журнал Harvard Business Review: «Data Scientist — самая сексуальная профессия XXI века».
В статье рассказывалось о Джонатане Голдмане, физике из Стэнфорда, который устроившись на работу в социальную сеть LinkedIn, занялся чем-то странным и непонятным. Пока команда разработчиков ломает голову над тем, как модернизировать сайт и справиться с наплывом посетителей, Голдман строит прогностическую модель, которая подсказывает владельцу аккаунта LinkedIn, кто еще из пользователей сайта может оказаться его знакомым.
С тех пор профессия Data Scientist не стала менее сексуальной, скорее наоборот. В 2016 году она возглавила кадровой компании Glassdoor. Не будем подробно останавливаться на том, почему сегодня эта профессия считается одной из самых высокооплачиваемых, привлекательных и перспективных в мире. Отметим лишь, что число вакансий в этом направлении продолжает расти по экспоненте. Согласно прогнозам McKinsey Global Institute, к 2018 году в одних только США понадобится дополнительно порядка 140-190 тысяч специалистов по работе с данными.
Неудивительно, что сегодня так много желающих освоить эту профессию. Давайте разберемся, кто же такой Data Scientist и какими навыками и знаниями он должен обладать.